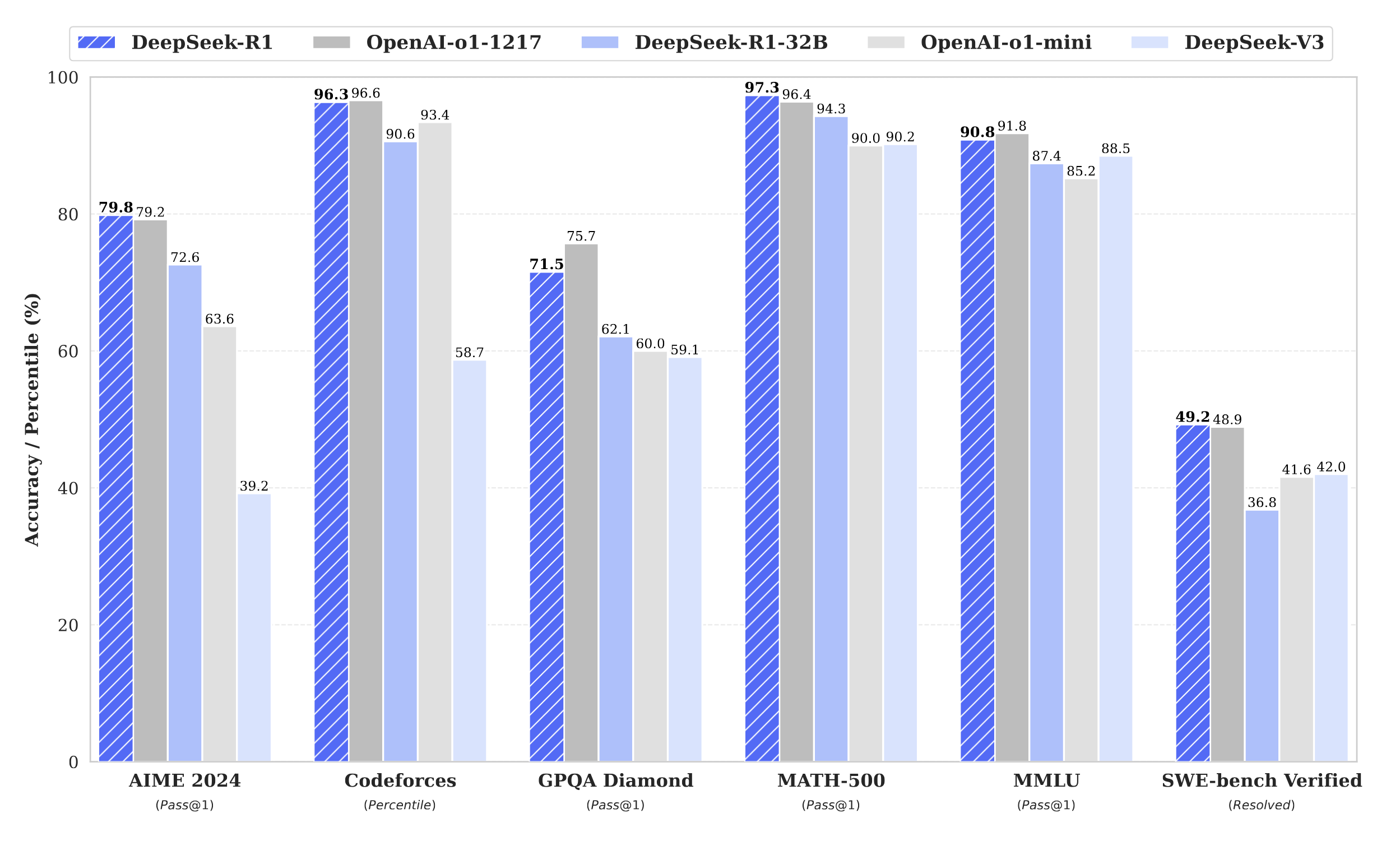
The paper introduces DeepSeek’s first reasoning models: DeepSeek-R1 and DeepSeek-R1-Zero (GitHub). The key findings are:
- RL is all you need for reasoning: Sophisticated reasoning - self-verification, reflection, and longCoTs - can emerge just by directly training a base LLM with RL, no CoTSFT data needed!
- You can distill reasoning to smaller models: Reasoning patterns can be distilled into smaller models, boosting their performance on reasoning tasks. The DeepSeek team released several distilled models (from 1.5B to 70B) based on Qwen2.5 and Llamma3 (GitHub).
- SFT + GRPO = SOTA reasoning: DeepSeek-R1, trained with both SFT and GRPO, either beats or matches OpenAI-o1 on reasoning tasks!